为了使程序执行速度更快,所以现有业务中大量使用了缓存机制,这里主要介绍下平时业务中用到的缓存的应用及缓存更新的策略。由于缓存涉及到的场景太多了,所以本次仅介绍书写代码时最最常用的基础知识 – 内存缓存。
一个轻量级请求中存在的缓存
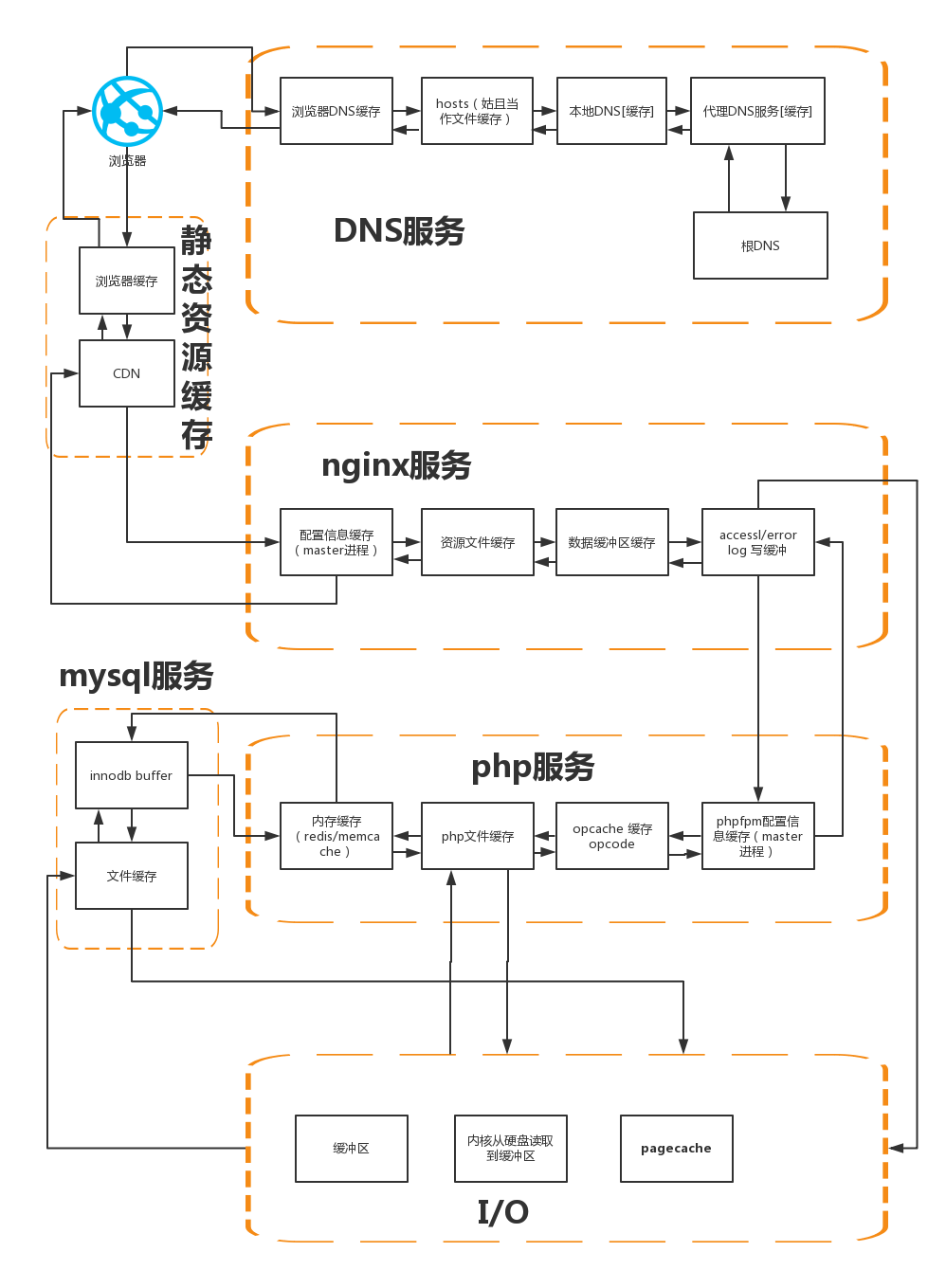
PHP内缓存的应用
一般模式
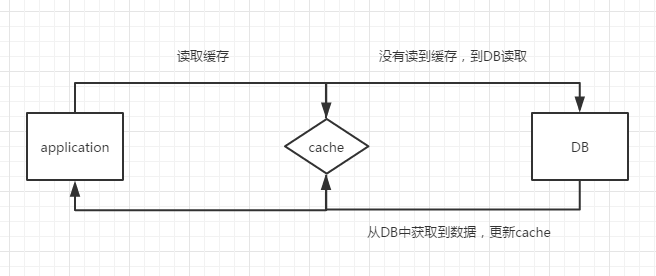
PHP中变量级别的缓存
适用场景:对于数据量较少,获取耗时,读多写少的情况
缺点:仅在生命周期内生效,进程间无法共享
class A {
public static $x = null;
public static $xx = null;
public function getX() {
if(!is_null(self::$x)) {
return self::$x;
}
//todo 耗时处理 START
$x = 'xxxx';
//todo 耗时处理 END
return self::$x = $x;
}
public function getXx($key) {
if(isset(self::$xx[$key])) {
return self::$xx[$key];
}
self::$xx = array();
//todo 耗时处理 START
$x = 'xxxx';
//todo 耗时处理 END
return self::$xx[$key] = $x;
}
}
这里可以思考下 geX 和 getXx 的应用场景
Redis 缓存
- 优点:高并发集群读写
- 常用数据结构: key/string/hash/set/list/sortedset
功能及应用场景
- key 键
- keys 线上服务杜绝使用
- string 字符串
- incr 原子性的计数器。对于并发的计数如PV/点击等可以使用 incr 存储,然后再入库
- setex set 某个值同时设置过期时间
- hash 哈希表
- 存储结构化的数据
- 避免将数据 json_encode 之后按照 key - value 方式存储,更加节省空间
- set 集合
- set元素最大可以包含(2的32次方-1)个元素,可以做 并集、交集、差集 的处理,比如 共同好友
- list 列表
- 一般作为队列使用。注意队列消费者使用阻塞模式的blpop
- sortedset 有序集合
- 一般存储有权重的数据,比如 排行榜
缓存常见问题
穿透
-
现象
其实就是查询一个不存在的数据,缓存中没有,然后又去数据库读,数据库中获取不到则不会更新缓存。这就导致每次的请求都会去存储层查询,失去了缓存的意义。
-
如何避免
如果有大量请求都穿透的话,数据库压力会非常大。所以在特定情境中需要对穿透的数据设置缓存,比如缓存一个标识,告诉请求没有数据,避免穿透。
缓存并发
-
现象
如果服务并发很高,当一个缓存失效时,可能出现多个请求同时查询存储,然后同时设置缓存的情况。如果并发很大,这可能造成存储服务压力过大。
-
如何避免
当请求发现没有缓存时,记录一个锁(需要原子性并且集群操作),然后再去数据库读取数据,最后更新缓存,删除锁。其他的请求当发现有这个锁则等待,直到锁解除,然后从缓存中读取数据。
一个容易复现的业务: 获取微信的 accessToken
背景:这个接口当时是每次刷新结果都会不一样
逻辑:微信接口请求需要带着 accessToken 参数,服务端有一个缓存保存 accessToken,如果调用的微信接口返回 accessToken 过期或者失效,就会再次获取 accessToken,更新缓存,然后重新调用微信接口。
现象:如果并发请求很多,而 accessToken 缓存恰巧失效。就会造成 accessToken 被并发请求互相抢着更新,一直无法获取到有效的 accessToken
雪崩
-
现象
缓存服务器重启或缓存集中在同一段短时间内失效,导致大量的强求都打到数据库或后端服务,造成服务压力过大。
-
如何解决
- 缓存服务器 高可用
- key的过期时间尽量分散
Redis 缓存过期
如何删除过期建?
- 当一个键被访问时,程序会对这个键进行检查,如果键已经过期,那么该键将被删除
- 底层系统会在后台渐进地查找并删除那些过期的键,从而处理那些已经过期、但是不会被访问到的键
Redis 内存回收机制
- volatile-lru -> remove the key with an expire set using an LRU algorithm
- allkeys-lru -> remove any key accordingly to the LRU algorithm
- volatile-random -> remove a random key with an expire set
- allkeys-random -> remove a random key, any key
- volatile-ttl -> remove the key with the nearest expire time (minor TTL)
- noeviction -> don’t expire at all, just return an error on write operations
什么时候设置过期时间
- 正常 key-value 存储,使用 expire expireat 等,在更新缓存之后更新
- 对于hash/set/list/sortedset 数据结构,要先更新过期时间,再添加/修改数据 为什么?
以hash结构举例,如果 key_test 中现在已经有
| a | b | c |
|---|---|---|
| 1 | 2 | 3 |
那么此时如果要新增一个域为 d 值为 4 的数据
$key = 'key_test';
$redis = new Redis();
$redis->hset($key, 'd', 4);
$redis->expire($key, 60);
一般情况下都会这么写,但是如果在执行 hset 之前,key_test 恰好到期了,那么缓存中就只剩下
| d |
|---|
| 4 |
这个时候缓存就成脏数据了,所以代码需要这么写
$key = 'key_test';
$redis = new Redis();
$rs = $redis->expire($key, 60);
if(!$rs) {
//当TTL更新失败时表明缓存已经丢失了,需要做回源更新
$redis->hmset('key_test', array('a' => 1, 'b'=> 2, 'c' => 3));
}
$redis->hset('key_test', 'd', 4);
TTL
/*
* 限制用户第一次访问站点之后,60s内不能访问
*/
$is_lock = isLock($uid);
lock($uid, $expire);
if($is_lock) {
return false;
}
function isLock($uid) {
$key = 'pre-' . $uid;
$redis = new Redis();
return $redis->exists($key);
}
function lock($uid, $expire) {
$key = 'pre-' . $uid;
$redis = new Redis();
$redis->setex($key, $expire, 1);
}
这个逻辑会造成用户第一次可以访问,如果再 60 s 内一直在刷页面的话,会导致 key 的 TTL 一直在更新,将永远不能再次访问成功
[server]$ redis-cli
127.0.0.1:6379> setex test_key 60 1
OK
127.0.0.1:6379> ttl test_key
(integer) 52
127.0.0.1:6379> setex test_key 60 1
OK
127.0.0.1:6379> ttl test_key
(integer) 59
127.0.0.1:6379>
注意,每次设置 setex 和 expire ,key 的TTL也会重新开始计算
更新缓存的策略
先看几种不同的更新策略(假设数据库和缓存更新必成功)
- 先更新缓存再更新数据库
- 先淘汰缓存再更新数据库
- 先更新数据库再更新缓存
- 先更新数据库再淘汰缓存
分析
-
先更新缓存再更新数据库
会有脏数据。
比如并发两个请求,A 请求要将数据修改为 aa , B 请求要将数据修改成 bb 。
当 A 请求先修改了 cache 为 aa ,等待数据库连接并且发送改库命令。此时 B 请求也来了将 cache 修改为 bb ,然后也执行了数据库操作,由于抢先发送了改库命令,此时数据库数据为 bb ,然后 A 请求修改数据库数据成功为 aa 。那么此时,cache 内数据为 bb,但是数据库内数据为aa
-
先淘汰缓存再更新数据库
会有脏数据。
比如此时数据库内数据为 cc ,并发来了两个请求,A 请求读取数据 , B 请求要将数据修改成 bb 。
请求 B 需要修改数据,先将缓存删除了,此时请求 A 读取缓存,穿透缓存后读取到数据数据为 cc ,然后将缓存设置为 cc 。然而 B 请求却将数据库内数据修改为了 bb 。以后的数据读取到的都是老数据。
-
先更新数据库再淘汰缓存
同样是查询和修改的请求并发。没有先删除 cache ,而是先更新数据库中的数据。在数据库的更新过程中,cache 依然有效,所以并发的查询操作都可以获取到 cache 的数据。但是当数据库更新操作成功后,cache马上失效了,后续的查询操作会穿透缓存把数据从数据库中拉出来,再更新入缓存中。
但是这个策略理论上也可能会存在有脏数据的可能。
比如还是数据库内数据为 cc ,并发来了两个请求,A 请求读取数据 , B 请求要将数据修改成 bb 。
请求 A 查询时缓存恰好过期了,然后去数据库读取到数据 cc ,在设置 cc 入缓存之前,请求 B 要完成数据库的更新和缓存的删除两步操作,等待 B 请求操作完毕之后,A 将 cc 写入缓存。 这种情况需要 1. 查询时没有缓存。2. 在改库操作之前查询到数据库。3. 在改库操作和删除缓存之后更新缓存。 但是改库操作执行时间一般要比查询时间长,同时改库还会表锁或行锁,查询请求必须在改库前进入并且改库后修改缓存,才能造成脏数据,概率很小。
-
先更新数据库再更新缓存
基本策略同先更新数据库再淘汰缓存,但是避免了删除缓存后的穿透现象,适用于超高并发的情景